
________________________________________________________________
◆データベース
この章ではAWSのデータベースについて学習していきます。
基本的なデータベースの基礎知識についてはCLFカリキュラムを参照してください。
ここでは事前に把握しているものとして進めていきます。
◆Amazon RDS
Amazon RDSはAWSが提供しているフルマネージドなリレーショナルデータベースサービスです。
複数のオープンソースソフトウェアのデータベースと互換性がありつつ、複数の機能により可用性や耐久性があります。
■サポートするデータベースエンジン
RDSでは以下のデータベースと互換性があります。
・Aurora
・MySQL
・PostgreSQL
・MariaDB
・Oracle
・SQL Server
・IBM Db2(2023年11月追加)

■Amazon RDSの特徴
CLFでも特徴をご紹介していますが、復習も合わせて改めてご紹介します。
・自動バックアップ
RDSは、インスタンス作成時にバックアップの保存期間を設定することができます。設定すると、自動的にデータベースのスナップショットを作成し、定期的なバックアップをS3へ保存することが出来ます。デフォルトでは7日間で0-35日間で設定可能です。0の場合はバックアップは作成されません。自動バックアップは設定した期間が過ぎると自動で削除されます。
自動バックアップ以外に手動でバックアップを取得することができ、手動で取得した場合は35日過ぎても自動で削除されることはありません。
・リードレプリカとマルチ-AZ配置
「リードレプリカ」と呼ばれる読み取り専用のデータベースを作成することができるため、読み取りトラフィックを分散させることができます。また、複数のAZへデータベースを配置する「マルチ-AZ配置」を使用することで、高可用性を確保し、データベースの冗長性を向上させることができます。
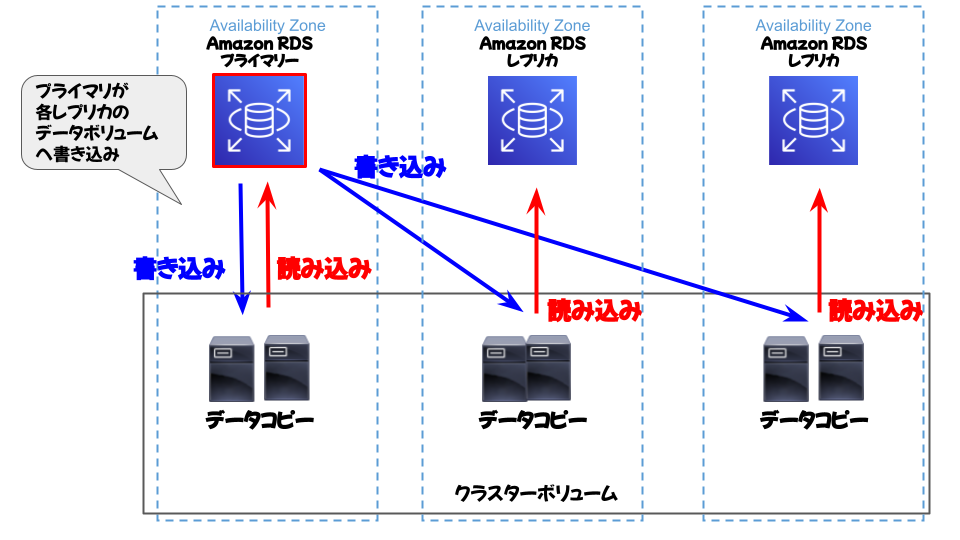
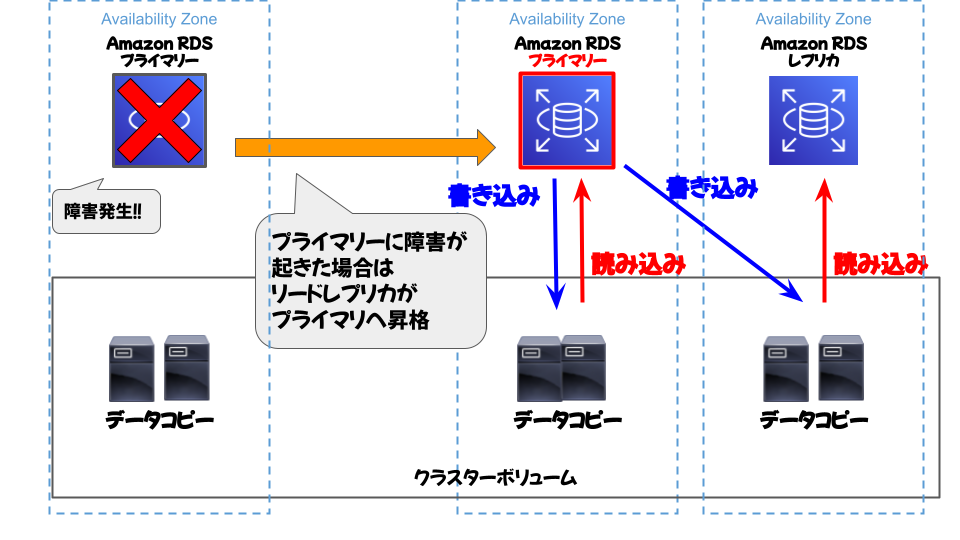
さらにそれに加えてフェイルオーバー機能もあり、プライマリデータベースに障害が発生した場合はリードレプリカが自動的にプライマリデータベースとして昇格する機能もあるため、より高可用性に長けているといえます。
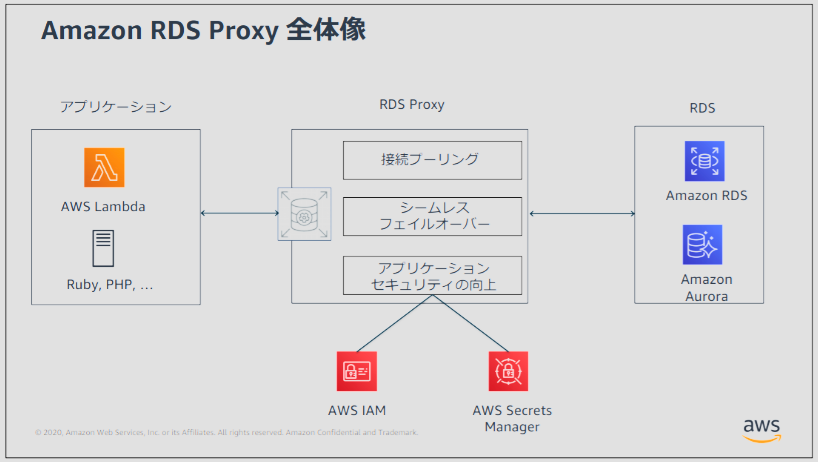
■RDS Proxy※New
RDS ProxyとはAmazon RDS 向けの高可用性フルマネージド型データベースプロキシです。 アプリケーションのスケーラビリティやデータベース障害に対するリカバリー、安全性の向上を実現します。
以下のような特徴があります。
・接続プーリングができる
接続プーリングは、接続したり、接続を切ったり、多数の同時接続をしていることに伴うオーバーヘッドを削減するための方法です。接続の開閉によるTLS/SSL のハンドシェイク、認証、ネゴシエーション機能などのCPU負荷を削減することができます。
・RDS Proxy の認証
データベースサーバーがネイティブのユーザー名 / パスワード認証しか対応
していない場合でも、RDS Proxy への接続はIAM認証を利用することができます。
アプリケーションコードに認証情報をハードコーティングしないことによるセキュリティレベルを向上させることができます。AWS Secrets Manager によるデータベース認証情報の⼀元管理も行うことができます。
・TLS/SSLが使える
データベースサーバーがTLS1.0/1.1しか対応していない場合でも、RDS Proxyとアプリケーション間の接続にはTLS1.2を利用することができます。
※RDS Proxy は AWS Certificate Manager (ACM) の証明書を使用します。
・フェイルオーバーによる高可用性
フェイルオーバーは、元のデータベースインスタンスが使用できなくなったときに、別のインスタンスに置き換える高可用性の機能です。フェイルオーバーは、マルチ AZ 設定の RDS DB インスタンスに適用されます。また、ライターインスタンスに加えて 1 つ以上のリーダーインスタンスが含まれている Aurora DB クラスターにも適用されます。
元の DB インスタンスが使用できなくなると、RDS Proxy はアイドル状態のアプリケーション接続を切断せずにスタンバイデータベースに接続します。アプリケーションからの再接続は不要になります。
◆Amazon Aurora
Amazon AuroraはRDSのデータベースエンジンの1つで、MySQLおよびPostgreSQLと完全な互換性があるデータベースです。元々Amazonがクラウドの普及に合わせて再設計したデータベースという背景があったりします。
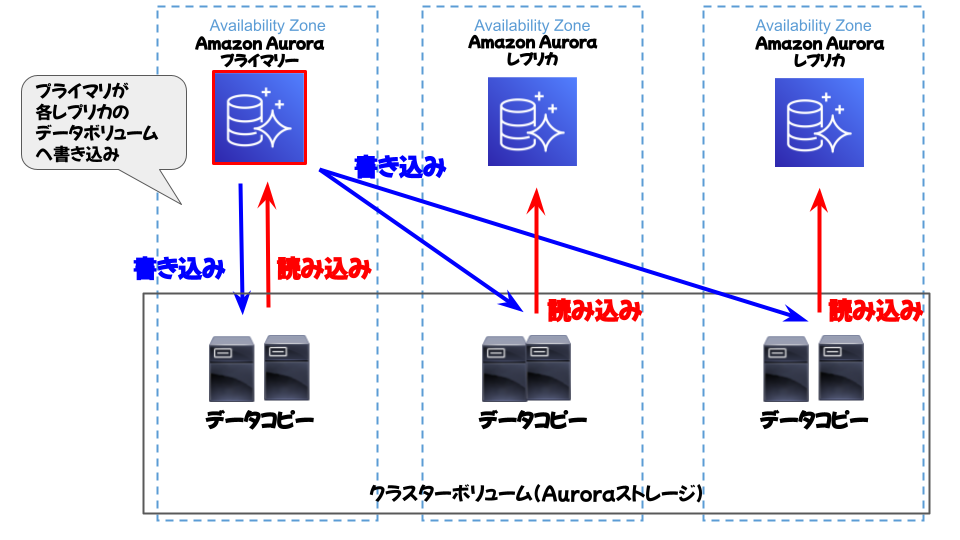
■Auroraの構成※New
AuroraはAurora DB クラスターと呼ばれる構成をしており、複数のAZ跨るクラスターボリュームとデータベースインスタンスで構成されています。大まかは動作としてはリードレプリカを同じと思って頂いて大丈夫です。
また、作成されるレプリカは「Aurora replica」と呼ばれ、最大15つ作成することができます。フェイルオーバー機能も同様に持ち合わせています。
■Auroraの特徴
・拡張性
Auroraは各インスタンスのストレージを10GB単位で最大128TBまで自動で拡張することができます。
・データベースクローン※New
Auroraはマネジメントコンソールからデータベースのクローンを作成することができます。
ただし、下記のような制約があります。
①ソースデータベースと同じリージョンにのみ作成可能
②クローンは最大15個まで可能
③クロスアカウントのデータベースクローンは未対応
④異なるVPCにクローンする場合は、サブネットが同じAZにマッピングされている場合のみ対応
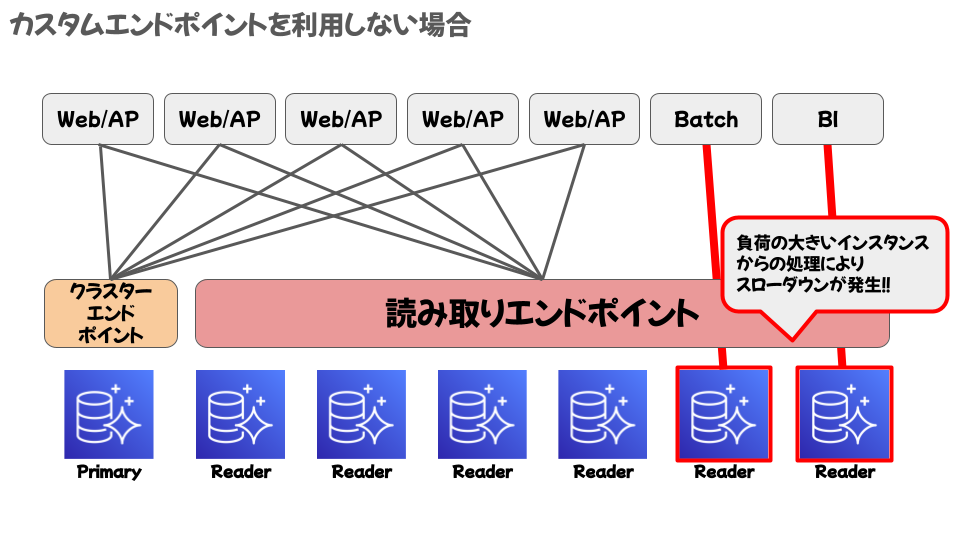
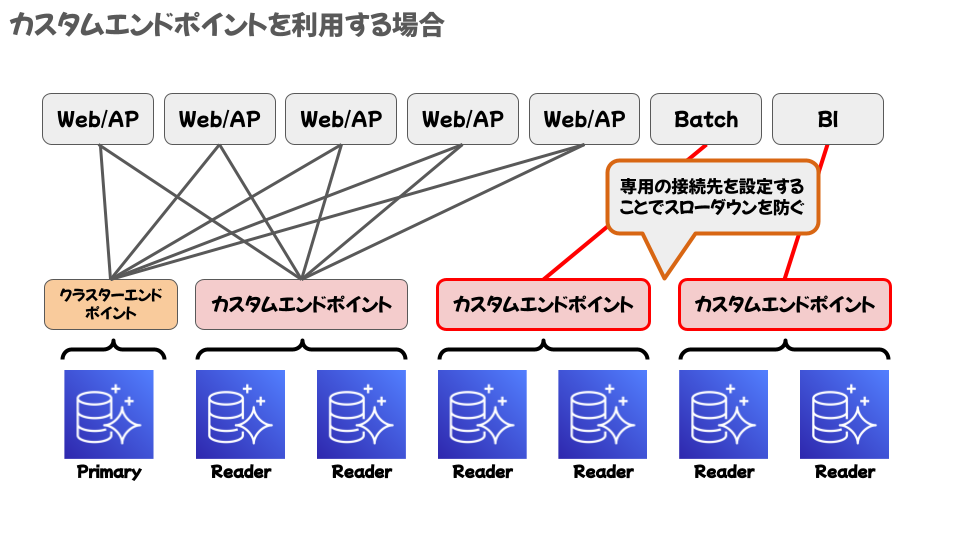
・カスタムエンドポイント※New
Auroraは、接続するインスタンスの組み合わせを自由に設定できます。
設定せずに運用すると、バッチ処理や等の負荷の大きい処理で読み取りを行う際に読み取りエンドポイントのリソースが枯渇してしまい、速度が低下する可能性があります。
そこで次の図のように、バッチ処理やBIがアクセスするエンドポイントを設定することで、速度の低下を回避できます。
◆Aurora Global Database※New
Aurora Global Databaseは、障害復旧環境を高速に構築できるレプリケーション機能です。
通常ではできなかった、異なるAWSリージョンにデータベースをレプリケートすることが可能になり、災害発生時にはセカンダリリージョンがプライマリに昇格されます。
利用するシーンとしては、常に同期されている必要がある財務・ゲームアプリケーション等のデータベースを運用しているサービス等で、Aurora Global Databaseを利用しておくことで常に異なるAWSリージョンへレプリケートが実行されているため、リージョン単位の障害に対しても対応することができます。
■Amazon Aurora Serverless※New
Amazon Aurora Serverlessは、通常のAuroraの機能を持たせた状態でサーバーレスの特徴を持たせたAuroraの設定です。そのため、利用がないときにはデータベースが自動的に停止します。
逆に言えば、利用する際には起動する必要性があることからリアルタイム処理や低レイテンシーを求めるサービスとの組み合わせには向きません。
ただし課金体制は起動していた時間のみであるため、利用する際に課題となるコスト削減が期待できます。
参照:https://aws.amazon.com/jp/rds/aurora/serverless/
◆Amazon DynamoDB
Amazon DynamoDBはAWSにおけるフルマネージド型のNoSQLデータベースサービスです。
主に低レイテンシーなアクセスが必要なアプリケーションやセッションデータを一時的に保存したい場合にも用いられることがあります。SQLのような複雑なデータベース処理はできないものの可用性・柔軟性が高いデータベースとなっています。
■DynamoDBの特徴
・スケーラビリティ
DynamoDBは、需要に応じて自動的にスケーリングできる柔軟な設計を持っています。読み取りおよび書き込みキャパシティユニットを設定することで、アプリケーションのトラフィックに対応できます。
・高可用性
DynamoDBは3つのAZでレプリケートされるため、高可用性です。
・Lambdaとの連携※New
サーバーレスサービスであるLambdaとの相性が良いため、サーバーレス開発によく用いられることが多いです。
■パーティションキー
DynamoDBはKey-Valueストアなので、パーティションキー(Key)に対してValueが格納されます。
DynamoDBテーブルの項目を識別するプライマリーキーはシンプルキー(パーティションキーのみ)、または複合キー(パーティションキーとソートキーの組み合わせ)で構成されます。
ソートキーはシンプルキーでパーティションを一意に特定できない場合に使います。
・プライマリーキーだけで絞り切れない場合、プライマリーキー以外の属性を使ってデータに効率的にアクセスできるようセカンダリインデックスを作成します。セカンダリインデックスにはローカルセカンダリインデックス(LSI)と、グローバルセカンダリインデックス(GSI)の2種類があります。
・ローカルセカンダリインデックス(LSI)
LSIは元のテーブルのパーティションキーと同じパーティションキーを使用しますが、異なるソートキーを持つことができるセカンダリインデックスです。さらに、元のテーブルのアイテムと同じパーティション内に格納されるため、実際のデータは元のテーブルと同じ制約(キャパシティユニットやストレージ)の下で利用可能です。そのため、テーブルのアイテムをパーティション内でソートおよびフィルタリングするための追加の検索オプションとして提供しています。
・グローバルセカンダリインデックス(GSI)
GSIは元のテーブルの異なるパーティションキーとソートキーを持つ、完全に独立したセカンダリインデックスです。元のテーブルとは別のストレージおよびキャパシティユニットを使用するため、クエリは元のテーブルのクエリとは独立してスケーラブルに処理されます。
■DynamoDB Accelerator(DAX)
DynamoDB Accelerator(DAX)とは、DynamoDBに特化した高可用性インメモリキャッシュです。高速なインメモリーキャッシュを使用して、DynamoDBからデータを取得する際のレイテンシーを低減し、リクエストの応答時間を向上 させることができます。
主に、読み込み負荷がかかるアプリケーションや読み取りのリアルタイム処理を求めるサービスに利用されます。ただし、書き込み処理が頻繁なケースには向いておらず、データの整合性やキャッシュの有効期限などの考慮が必要な面もあります。
■DynamoDBの有効期限 (TTL)
DynamoDBの有効期限 (Time-To-Live:TTL)とは、データベースから自動的にテーブルが削除されるようにするための機能のことです。TTLを使用すると、テーブルの保存期間を指定することができるため、特定の時間(1日、30日、60日など)ごとにテーブルを削除したいケースなどに用いられます。
■Amazon DynamoDBグローバルテーブル
Amazon DynamoDBグローバルテーブルとは、複数のAWSリージョンにわたって分散配置されたテーブルであり、データの冗長性と可用性を向上させるために使用されます。リージョンを超えたデータベース同士はデータを同期しており、1つのリージョンに変更があった場合には他のリージョンのテーブルにも伝わります。
そのため、世界中に利用者がいるが、データは同期している必要がある要件にも対応することができます。
■Amazon DynamoDBキャパシティーユニット
Amazon DynamoDBキャパシティーユニットとは、読み込み/書き込みの容量のことです。 読み込みキャパシティーユニット(Read Capacity Unit:RCU)と、書き込みキャパシティーユニット(Write Capacity Unit:WRU)があり、各々に課金が発生します。稼働させているだけで課金されます。DynamoDB Auto Scalingは特に注意が必要です。
読み込み(4KB/1秒以下)
・強力な整合性のある読み込みリクエスト→1つの読み込みリクエストユニット
・結果整合性のある読み込みリクエスト→1/2(0.5) の読み込みリクエストユニット
・トランザクション読み込みリクエスト→2つの読み込みリクエストユニット
書き込み(1KB/1秒以下)
・書き込みリクエスト→1つの読み込みリクエストユニット
・トランザクション書き込みリクエスト→2つの読み込みリクエストユニット
DynamoDBにはテーブルで読み込み/書き込みを処理するための読み込み/書き込み容量モードがあります。容量を事前に設定するプロビジョンドモードと、柔軟に変更できるオンデマンドモードの2つです。
オンデマンドモードのテーブルでは、読み込みおよび書き込みスループットを指定する必要はありません。ワークロードが急激に増減するようなサービスにはオンデマンドモードを使用します。
プロビジョンドモードのテーブルでは、読み込みと書き込みの回数を指定する必要があります。
DynamoDB Auto Scalingを使用すると、トラフィックに応じて、テーブルのプロビジョンドキャパシティーを自動的に調整できます。これにより、コストの予測をするために、設定したリクエストレート以下に維持されるようにDynamoDBを制御できます。
ここで、読み込み/書き込みのキャパシティーユニットの上限をあまりに大きな値に設定していると、莫大な料金がかかる恐れがあります。必要最小限の値を設定する必要があります。
◆Amazon ElastiCache
Amazon ElastiCacheは、厳しい応答時間が要求される場合などに使用される完全マネージド型のインメモリキャッシュサービスです。よく利用するデータをキャッシュと呼ばれる一時保存領域に保存することで、データのやり取りを高速に行うことができます。
■ElastiCacheの特徴
ElastiCacheはインメモリーのサービスであるため、ハードディスクに保存するよりもさらに高速なデータのやり取りが可能となります。インメモリーとは、ソフトウェアを実行する際、使用するデータのすべてをメインメモリー(RAM)上に読み込み、ストレージ(外部記憶装置)を使わない方式です。
主な目的としては、データをキャッシングすることでデータベース(RDSなど)の負荷を減らし、Webアプリケーションのパフォーマンスを向上させることです。
その他にセッション情報を保持するために使用したり、ランキングやレコメンデーションの実装に使うための便利な機能を有しています。
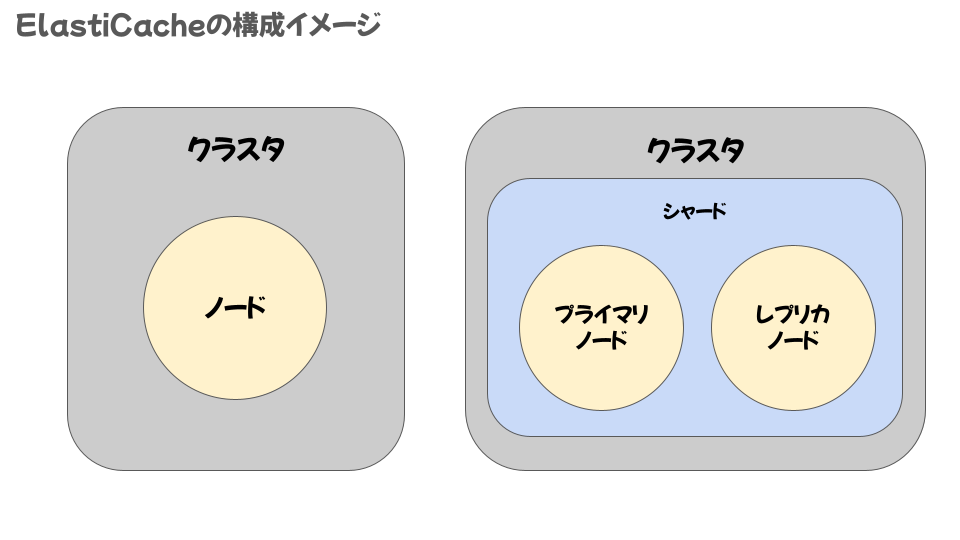
■ElastiCacheの構成
ノード、シャード、クラスターという3つの要素から構成されています。
・ノード
ElastiCacheの最小単位であり、実際にデータが保存される場所となります。設定したノードタイプによってメモリーのサイズなども変わります。
・シャード
ノードをまとめるグループをシャードと呼びます。AmazonElastiCache for Redis(後述)でのみ登場する概念であり、読み書きが可能なプライマリノードと読み込みのみ可能なレプリカノードを
最大5つ登録可能です。1つのシャード内に複数のノードが存在する場合はノード間でデータが共有されます。
・クラスター
ノードもしくはシャードをまとめる論理グループをクラスターと呼びます。クラスター毎にキャッシュエンジン(後述)を選択することができ、同じクラスター配下のノードはすべて同じキャッシュエンジンで動作します。
■2つのキャッシュエンジン
ElastiCacheは「Redis(レディス)」と「Memcached(メムキャッシュディー)」という2種類の高パフォーマンスなインメモリーデータストアを提供していて、アプリケーションのセッション情報や、データベースクエリ結果のキャッシュするなどの利用シーンで使用されます。
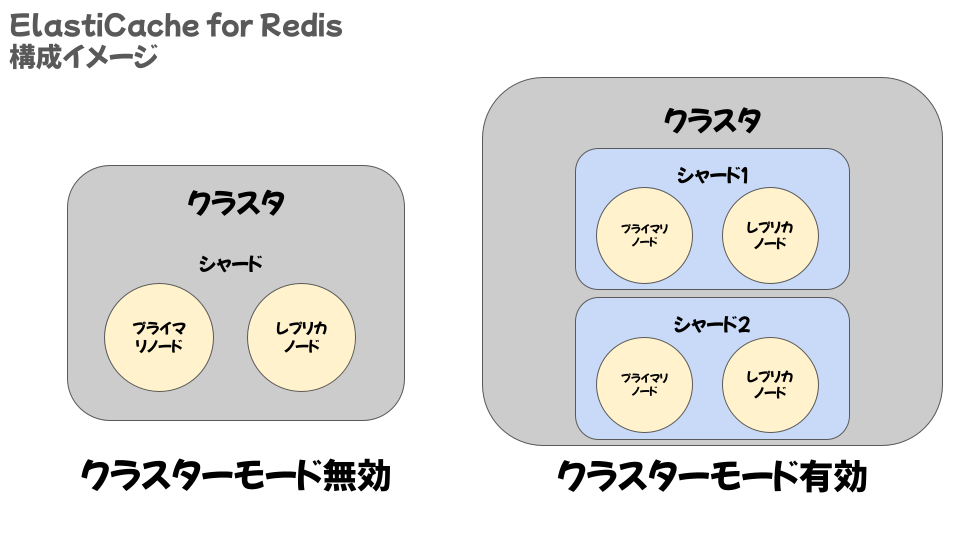
・Amazon ElastiCache for Redis
クラスター化に対応していてレプリケーションや自動フェイルオーバーなど機能が充実しています。また、データ永続化にも対応しています。
クラスターモードを有効化すると、シャードを複数保持することができるようになります。シャードが複数あることでデータを分割して処理することが可能となり、読み書きが負荷分散されます。そうすることで可用性を高めボトルネックを減らすことができます。
・Amazon ElastiCache for Memcached
シンプルで、メモリーの使用効率が高いデータストアです。シャードは存在せず、クラスターの中に1〜40個のノードを持つことができます。単純なデータ型でよい場合やマルチスレッドを使用する場合に適しています。一方で、データ永続化には対応していません。
最後に小テストをご用意しましたので、チャレンジしてみましょう。
データベース